Содержание
Доброго времени суток, уважаемые читатели delajblog.ru!
В статье о том. как WordPress генерирует дубли страниц (документов) в древовидных комментариях я рассказал в прошлой статье. Полазив по популярным сайтам обнаружил, что такая проблема есть у многих блогов. Но у многих её и нет — значит решили эту проблемку. Как оказалось существует несколько способов её решения. Итак задача — исключить дубли документов из индекса Гугл.
Удаление в инструменте для для веб-мастеров
Поисковая система Google предоставляет такую возможность. Для этого заходим в инструменты для вебмастеров своего блога. Последовательно нажимаем Конфигурация, Параметры URL, настройка параметров URL.
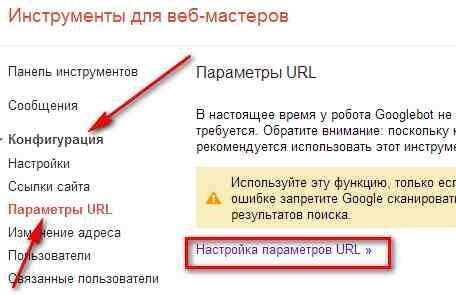
Далее попадаем на страницу, где видим приснопамятный параметр rep
Нажимаем Добавление параметра.
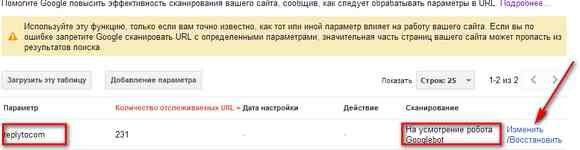
Видим, что параметр replytocom обрабатывается на усмотрение робота (вот он гад и обработал — засунул в индекс, что не нужно!). Нажимаем на ссылку Изменить.
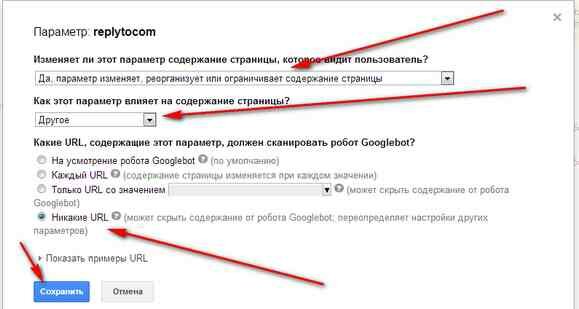
И выставляем параметры, как указано на картинке, нажимаем кнопку Сохранить.
Делаем редирект в .htaccess
В корневой папки сайта имеется файл .htaccess, который управляет поведением сервера, на котором находится сайт. Если такого файла нет, то его создают в обыкновенном блокноте, только внимательно смотрим за его расширением.
Вставляем в этот файл следующие строки:
RewriteCond %{QUERY_STRING} replytocom=
RewriteRule ^(.*)$ /$1? [R=301,L]
Теперь будет редирект 301 на оригинальную статью. содержащую древовидные комментарии. Файл .htaccess заливаем в корневую папку сайта на сервере.
Немного об индексации страниц запрещенных в robots.txt
Файл robots.txt всегда находится в корне сайта (блога) на сервере и предназначен для управления роботами поисковых систем. Кстати сказать, что он необязателен для исполнения поисковыми роботами, и некоторые поисковики не всё делают, что в нем написано. Этот файл имеет стандарт написания и состоит из различных директив, например,
Disallow: /?s?
Такая директива запрещает роботу (боту) сканировать и индексировать все веб-страницы содержащие в своём адресе символ «s». Но на самом деле дело обстоит несколько иначе. Так, страница запрещенная в файле роботс, МОЖЕТ попасть в поисковый индекс, если на неё есть ссылка с другой страницы. Особенно четко это видно у гугла. И как, советует сам гугл, документы, которые не будут индексироваться, должны содержать мета-тег:
<meta name=“robots” content=“noindex,nofollow”>
Таким образом, думать, что для запрета доступа к документу и не попадания в индекс, её достаточно закрыть в роботс, означает думать не правильно. Кстати сказать, совсем недавно я думал именно так.
Стоит обратить внимание на такую ситуацию: имеется дубль кого-либо документа, в котором стоит метатег с “noindex,nofollow” и сам дубль закрыт от индексации в роботс. По идее, такой документ в индекс не попадёт, ведь мы его дважды закрыли в роботс и метатег запрета поставили. Но, он может попасть в индекс по той причине, что поисковый бот придёт, посмотрит в роботс, узнает, что доступ закрыт и уйдет, тем самым он метатег запрета и читать не будет. Получается, что нужно убрать запрет в роботс и тогда бот прочитает метатег запрета и не будет индексировать страницу.
С уважением, Александр



Здравтсвуйте! Спасибо за такую понятную статью) У меня параметра replytocom в webmasters не было и я его добавила сама, хотя в индексе они были. Дальше сделала все как вы советовали. Надеюсь, что правильно.
Удачи!
А вот такой url тоже по сути дубль? https://delajblog.ru/udalenie-replytocom-iz-rezultatov-poiska-google#comment-1559
Да
Не вводите людей в заблуждение: https://delajblog.ru/udalenie-replytocom-iz-rezultatov-poiska-google#comment-1559 — такой адрес это не дубль. Тут к ссылке добавлен якорь и это не считается отдельной страницей
Не буду спорить с Вами. Ваше мнение — приветствуется. Никого ни в чем убеждать не собираюсь. Если по разным URL адресам открывается одна страница, то это — дубль (ИМХО).