Содержание

Для того, чтобы посетители смогли найти любой сайт в поисковике его должен увидеть и проиндексировать поисковый робот. Эта специальная программа, которая ходит по сайтам и заносит их в свою поисковую базу. Но не все найденные веб-страницы попадают в поиск. И какие? И так первый фильтр.
Веб страницы, которые не попадают в поиск:
- сервер ответил:»нет доступа» -код ответа 404;
- установлено перенаправление -код ответа 301;
- нет доступа ошибка DNS: сервер ответил — dns error;
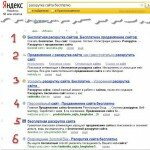
Такие страницы стопроцентно в поиск не попадают. Отсюда вывод: проверяйте, какой ответ дает сервер. Проверить можно, например, в Яндекс вебмастер. заходим на страницу проверки ответа сервера. 
В соответствующее поле вводим адрес проверяемой веб страницы и жмем кнопку «Проверить». И смотрим результат.
Очень хорошо — ответ 200 ОК. Т.е. у этой страницы есть шансы попасть в поисковый индекс (с кодом ответа 301, 404,dns error шансов вообще нет), а почему только шанс? А дело в том, что все страницы с кодом 200 попадают в следующий фильтр.
Код ответа 200, но не попадут в поиск
Или если и попадут, то не будут находиться в топе поисковика. К ним будет применен соответствующий коэффициент, что они «плохие»
- переоптимизация;
- спам;
- зарекламленность;
- дорвеи.
Останутся в поиске только страницы с полезной информацией и которые отвечают на запрос пользователя, оригинальные и уникальные.
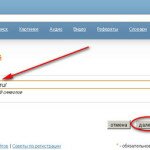
Примечание. Что такое оригинальный текст вполне понятно — текст должен быть единственным в интернете. Проверяется легко -имеется куча сервисов, например, text.ru

Вставляете текст и жмете на кнопку «Проверить уникальность» и всё станет ясно и даже дадут ссылки с каких сайтов текст «позаимствован»

А вот, что такое за требование как «Оригинальность»?
Современные поисковики стали настолько умные, что умеют отличать неоригинальные тексты. Т.е. если, вы например, взяли из интернета какой-нибудь текст и своим словами пересказали его, он проходит тест на уникальность, но не является оригинальным, потому, что он не содержит ничего нового.
Вывод: уникальности в тексте уже мало, надо что -то своё добавлять в текст.
Документы в индексе
После того, как документы прошли два фильтра они попадают в поисковый индекс — специальная база данных, в которой легко можно найти нужный материал. Когда пользователь задает вопрос поисковику, он выбирает в этой индексной базе документ, наиболее отвечающий запросу. Пользовать в выдаче видит все сайты отвечающие его запросу.
А теперь, всё про тоже, но другими словами.
Поисковые машины интернета имеют четыре функции – это crawling (ползание), индексирование, расчёт релевантности, предоставление результатов пользователю.
Ползание (crawling)
Автоматизированный робот или сканер («паук») по заданному ему алгоритму обходит всю сеть интернет, при этом паук посещает все веб-страницы всемирной сети. В своём поиске роботы используют гиперссылки на веб-страницах по которым и осуществляют переходы.
Через ссылки, роботы поисковых систем могут достигать многих миллиардов взаимосвязанных документов интернета. Важно понять, что «паук» посетит только ту страницу, на которую ведёт гиперссылка, и если таковой нет, то такая страница невидима для «паука». После посещения страницы «паук» «вытаскивает» со страницы часть информации (сколько и объём информации зависит от алгоритма конкретной машины.
Обратите внимание, что робот собирает только часть посещенной им веб страницы) и записывает всё на гигантские жесткие диски, которые находятся в специальных дата центрах разбросанных по всему миру. Т.о. первое, что сделала поисковая машина – это запустила «паука», который посетил весь интернет и записал куски веб страниц на жесткий диск в дата центрах.
Колоссальный объем информации (миллиарды веб-страниц!) находящейся в дата центрах обрабатывается мощнейшими компьютерами, которые обеспечивают выдачу пользователю испрашиваемой им информации.
Индексирование
На компьютерах дата центров записанная информация индексируется, т.е. каждая веб страница по заданному алгоритму обрабатывается и каждой странице присваивается индекс, т.е. «важность», или значимость этой станицы для пользователя. Теперь, когда пользователь в поисковике набирает запрос, поисковая машина поищет этот запрос уже в своих индексах.
Релевантность
Когда пользователь набирает запрос в поисковой системе, он заставляет её сделать две вещи: во-первых, отдать пользователю адекватный ответ (релевантность, проще говоря – это максимальное соответствие между запросом пользователя и ответом поисковой машины) и второе – ранжировать результаты выдачи (важность, значение), т.е. чем релевантнее ответ, тем выше он находится в поисковой выдаче.
Для поисковой машины релевантность – не просто выдача пользователю веб страницы, на которой находятся искомые им слова (ключевые слова или фразы, которые пользователь вбил в поиске), но выдача полезной ему информации. В настоящее время на релевантность влияет огромное число факторов, т.е. на поисковую выдачу результатов пользователю влияет множество факторов, которые определяются алгоритмами работы поисковых машин.
В настоящее время, одним из главных факторов, влияющих на ранжирование (и соответственно, выдачу в более высоких позициях) является популярность сайта или отдельной веб-страницы. Т.е. поисковая машина определяет, чем популярнее документ, тем он ценнее и соответственно происходит выдача на верхние позиции в поисковой выдачи. Например, чем популярнее данный блог (чем больше ссылок будет направлено на этот блог с других сайтов), тем более высокое место он займёт в поисковой выдачи.
Продолжение в следующей статье.

спасибо, действительно тонкости работы поисковиков надо знать)