Доброго времени суток, уважаемые читатели блога delajblog.ru.
Доброго времени суток, уважаемые читатели блога delajblog.ru.
В настоящее время в сети интернет содержится огромное количество информации и для её нахождения созданы специальные поисковые системы, задача которых найти в этом море информации нужную пользователю. Пользователь у себя на компьютере, который подключен к Сети, в браузере (Internet Explorer, Mozilla Firefox, Opera, Google Chrome и т.д.) подключается к такой системе (наиболее популярные в русскоязычном интернете – Яндекс, Гугл), и в соответствующем поле набирает нужный запрос (например, «Как сделать блог») и в результатах ему выдаётся перечень сайтов на которых и содержится ответ на заданный запрос.
Любая поисковая система интернета состоит из нескольких основных компонентов:
Spider (паук) – программа, которая скачивает веб – страницы (или документы, что одно и тоже) с сайтов подобно браузеру. При этом она не может работать с графической информацией, а работает исключительно с html-текстом.
Вот как видна веб-страница в браузере.

А вот та же веб-страница скачанная пауком.
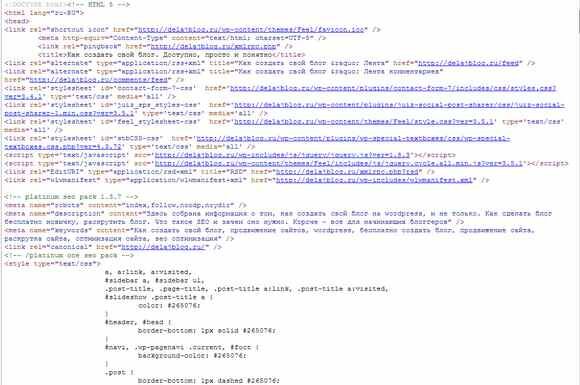
Обратите внимание, что графику паук не видит.
Crawler – программа ищет в скачанной странице ссылки и даёт команду пауку идти по этим ссылкам (и соответственно скачивать веб-страницы с этих ссылок).
Indexer – программа анализирует html-текст — разбирает его на составляющие: заголовки, таблицы, выделение текста, форматирование текста и т.п.
Database – база данных в которой хранятся все скачанные и обработанные html страницы.
Search engine results engine – система выдачи результатов поисковой машины. Т.е. здесь решается какую информацию и в каком виде выдать пользователю на его запрос.
Обратите внимание, что когда пользователь набирает в браузере свой запрос, то поисковая машина не ищет ответ на запрос пользователя по всему интернету, а обращается к своей базе данных. Отсюда несколько выводов:
Каждая такая система ищет необходимую информацию в своей базе данных (у Яндекса своя и у Гугла тоже – своя). Это к тому, что информация на сайте может изменится, а выдаваться будет сохраненная в базе информация. И важнейший вопрос — это как часто поисковик эту свою базу обновляет. Обновление такой базы называется апдейт. У Яндекса обновление происходит приблизительно за неделю, а Гугл – практически каждый день. Посмотреть апдейты Яндекса можно например на сайте http://tools.promosite.ru/
Вот так выдается информация пользователю.
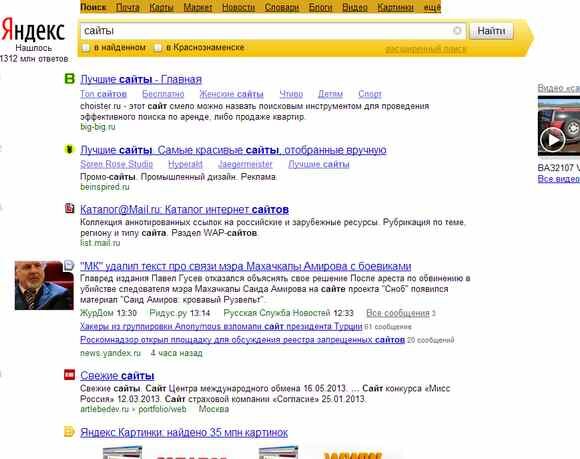
Т.о. выдача состоит из нескольких страниц (на рисунке показана первая страница) на которой представлены ссылки на документы, которые по мнению поисковика отвечают на запрос пользователя. Документы располагаются по релевантности, т.е. документы, которые наиболее полно отвечают на запрос пользователя располагаются выше.
Процесс выстраивания документов по релевантности называется Ранжирование и у каждой системы алгоритм свой.
Вот так (в самом грубом представлении) работают поисковые машины интернета.